
På bare 3 sekunder kan en AI som aldri har hørt deg snakke imitere stemmen din perfekt. Dette er den siste prestasjonen til Microsofts kunstige intelligens - VALL-E tekst-til-tale-modellen, som kan kopiere hvem som helsts stemme etter ønske med bare 3 sekunders tale.
Microsoft VALL-E vil imitere stemmen vår etter bare 3 sekunders tale
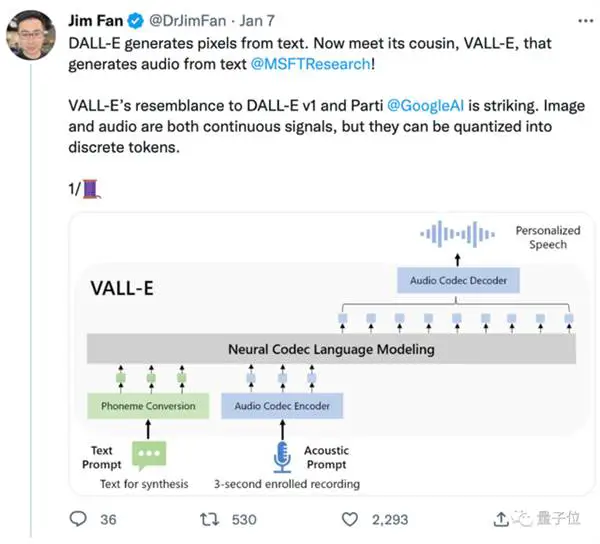
Den stammer fra DALL E, men spesialiserer seg på lydfeltet, og tekst-til-tale-effekten ble populær etter at den ble utgitt på nettet.
Noen brukere sa at hvis VALL·E og ChatGPT kombineres, vil resultatet bli fantastisk. For andre ser det ut til at dagen da det blir mulig å foreta videosamtaler med AI ikke er langt unna. Det er til og med de som fleiper med at etter at AI har tatt vare på forfatterne og malerne, er de neste stemmeskuespillerne.

Men hvordan imiterer ALL·E en "uhørt" lyd på 3 sekunder?
ALL-E analyserer lyd med språkmodeller. Den syntetiserer tale basert på AI "uhørte" lyder, det vil si null-sample læring.
Den tradisjonelle tekst-til-tale-løsningen er i utgangspunktet en pre-workout-modus sammen med en finjustering. Hvis det brukes i et null eksempelscenario, vil det resultere i dårlig likhet og naturlighet i den genererte talen.

Basert på dette kom VALL-E ut av ingenting, og foreslo en annen idé enn den tradisjonelle vokalmodellen.
Sammenlignet med den tradisjonelle modellen som bruker Mel-spekteret til å trekke ut funksjoner, tar VALL-E direkte talesyntese som en oppgave for språkmodellen, førstnevnte er kontinuerlig og sistnevnte er diskret.
Spesielt er den tradisjonelle talesynteseprosessen ofte banen til "fonem → mel-spektrogram (mel-spektrogram) → bølgeform".
Men VALL -E transformerte denne prosessen til "fonem → diskret lydkoding → bølgeform":
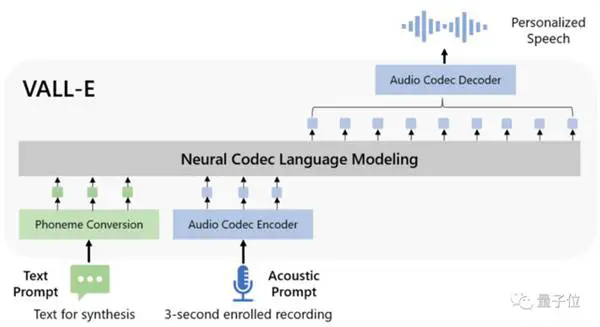
Når det gjelder modelldesign, ligner ALL-E også på VQVAE. Kvantiserer lyd til en serie med diskrete tokens. Den første kvantizeren er ansvarlig for å fange opp lydinnholdet og identitetsegenskapene til høyttaleren, mens den andre kvantizeren er ansvarlig for signalforfining. som høres mer naturlig ut:
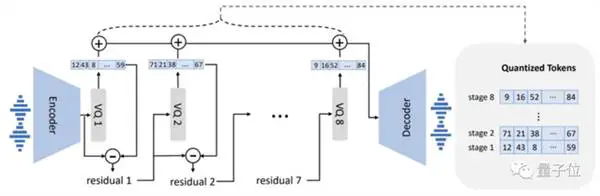
Deretter betinget av teksten og 3-sekunders lydmelding, sender den autoregressivt ut en diskret lydkoding:
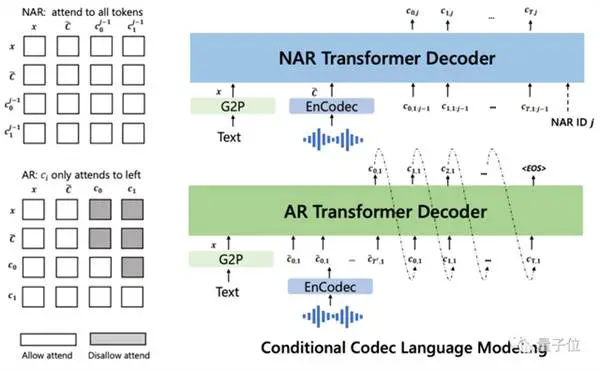
Men ikke bare det, i tillegg til null-sample talesyntese, støtter VALL-E også stemmeredigering og stemmeinnhold kombinert med GPT-3.
Den omgivende bakgrunnslyden kan også gjenopprettes
Å dømme etter de syntetiserte vokaleffektene, kan VALL-E gjenopprette mer enn bare høyttalerens klang.
Ikke bare er tonehøyden imitert på stedet, men den støtter også en rekke forskjellige talehastigheter. For eksempel er dette to forskjellige talehastigheter levert av VALL-E når den samme setningen blir sagt to ganger, men tonelikheten er fortsatt høy:
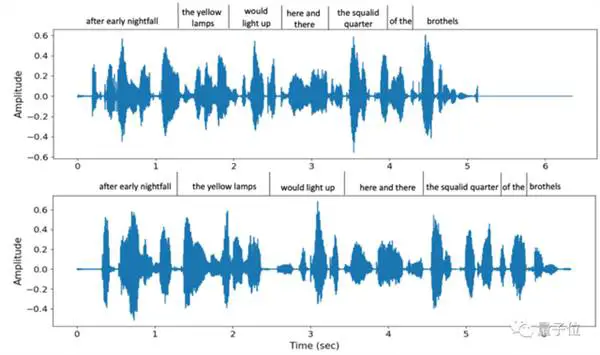
Samtidig kan bakgrunnslyden til den andre parten også gjenopprettes nøyaktig.
I tillegg kan VALL-E etterligne en rekke av høyttalerens følelser, inkludert flere typer som sint, søvnig, nøytral, glede og kvalme.
Det er verdt å nevne at datasettet som brukes til VALL·E-treningen ikke er spesielt stort.
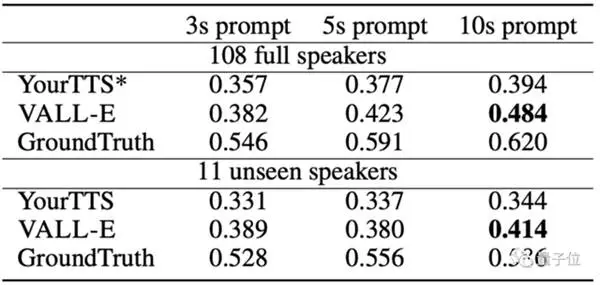
Sammenlignet med OpenAIs Whisper, som krevde 680.000 7.000 lydopplæringstimer og bare brukte mer enn 60.000 høyttalere og XNUMX XNUMX treningstimer, overgikk ALL-E forhåndstrent tekst-til-tale når det gjelder likhet med Model YourTTS tekst-til-tale.
Videre hørte YourTTS stemmene til 97 av 108 høyttalere på forhånd under treningen, men den kommer fortsatt til kort VAL-E i selve testen.
Når det gjelder feltene der det kan brukes:
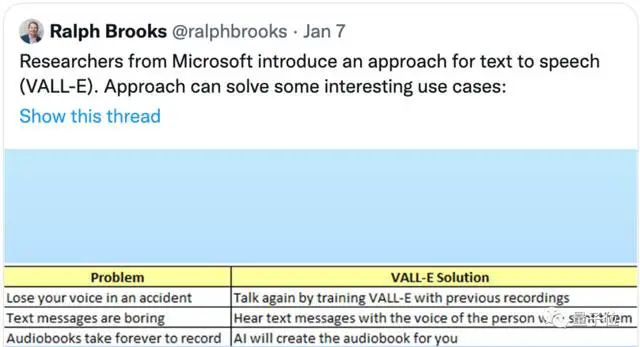
Ikke bare kan den brukes til å etterligne din egen stemme, for eksempel å hjelpe funksjonshemmede å fullføre en samtale med andre, men du kan også bruke den til å snakke for deg når du ikke vil. Den kan selvfølgelig også brukes til lydbokopptak.
VALL-E er imidlertid ikke åpen kildekode ennå, og du må kanskje vente litt lenger for å prøve den ut.
På tilbud på Amazon







